In this project, I use neural network to classify music by genre, the motivation being that classifying music by genre manually is time-consuming and tedious.
Large digital music collections have become more prevalent thanks to cheaper storage, more widespread broadband internet infrastructure and digital music distribution services.
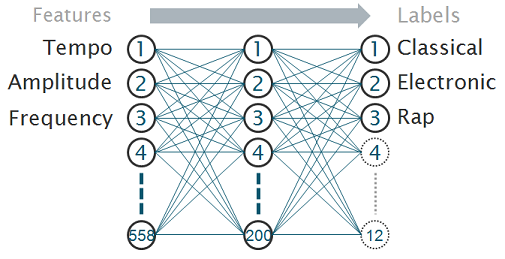
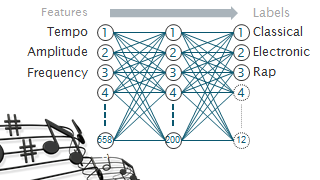
We decided to use a neural network because we have many examples (songs) available, and can collect any number of features per song. A feature is any number derived from the example which may be the song's length, average frequency, tempo, and so forth. Setting up a neural network is a fairly straightforward process, in theory:
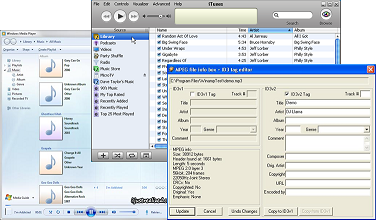
The first step is to collect your examples and classify them. In our case, we classified songs into genres such as blues, classical or hip-hop. We used iTunes as a standardized classification scheme to make our experiments repeatable.

Source: Apple iTunes
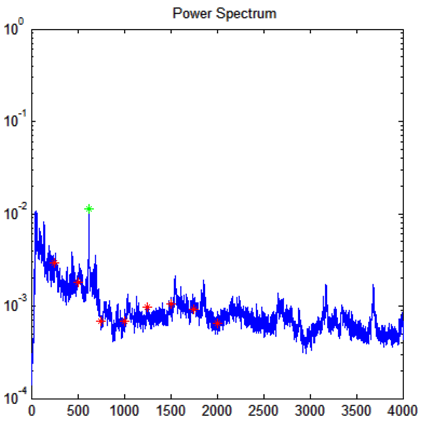
Feature selection is a very important step for the success of your neural network. We primarily used frequency data and tempo to characterize each song. We used a fast Fourier transform to determine which frequencies were dominant in the song, and recorded the amplitude of specific frequencies informed by the ranges of various musical instruments:
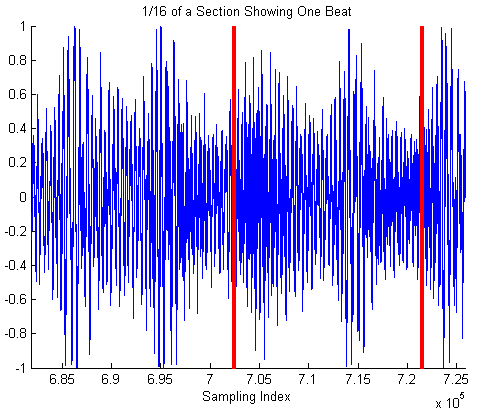
Tempo was determined using an existing algorithm from Columbia University's LabROSA-coversongID MATLAB library:
Each song takes roughly 30 seconds to process, so computations were run overnight. When a corrupt file was encountered our algorithm sometimes halted, so we only processed 450 songs in 3 genres instead of the planned 1200 songs in 12 genres.
Our actual neural network was a typical linear MLP, feed-forward with k-fold cross validation. It had variable hidden nodes and was built using MATLAB's NetLab package.
Our results for 3 genre classes are below, about midway between perfect accuracy and a blind guess. Training accuracy is the percentage of music correctly classified by the algorithm, out of a pool of examples it has already seen and used for training. Validation accuracy is for examples it has NEVER seen, which is a better test of the algorithm.
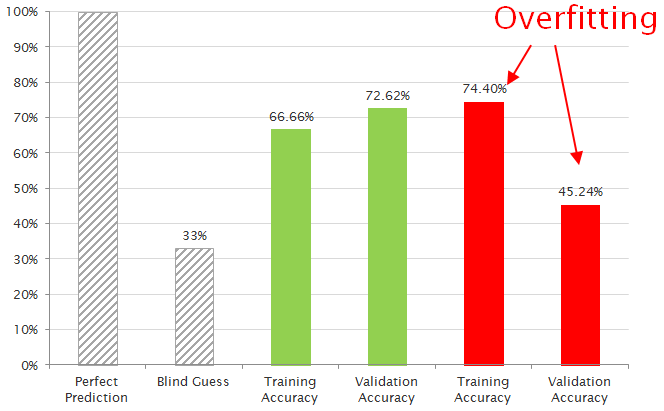
Best (green): 250 hidden nodes, 3-fold validation, 2000 epochs
Worst (red): 50 hidden nodes, 4-fold validation, 1500 epochs
For the "worst" result, the much lower validation accuracy suggests overfitting, or TOO much training. The algorithm is trying to look for music which more precisely matches those examples which it has already seen, which is an unreasonable expectation for this classification problem.
We were also able to run a few tests using 12 genres, with less stellar performance, though still much better than a blind guess:
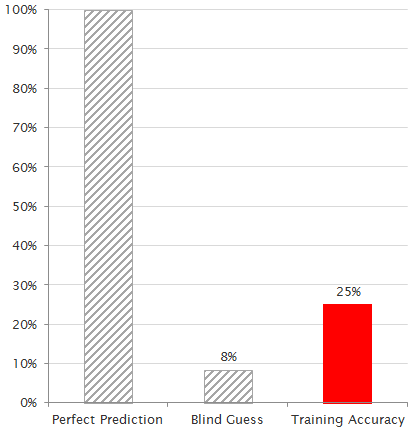
200 hidden nodes, 3-fold validation, 1750 epochs
We believe the main reason for this difficulty is that some genres of music are virtually indistinguishable, and many songs fall between two genres, such as Alternative and Rock.
The MP3 format is also innately lossy, so some audio data which may be undetectable by humans but useful for classification is no doubt lost. Furthermore, lengthy Pre-processing and sensitivity to data variation ensures that any adjustments or refinements require long-term planning.
Perhaps most damning is that a k-nearest neighbor analysis fails, which would foreshadow network failure because it suggests that there may not be as much actual correlation between our selected features and the known classifications of the training set.
What this suggests is that better feature selection is required to improve accuracy. For the scope of this project, we did not have time to investigate further. A different classification source may also help to provide more fine-grained classification of certain songs - one recommendation might be
Allmusic.com, where the scheme might use genre as well as style.
Overall, the results are promising, though there is obviously room for improvement. The program at least serves as a proof of concept, showing that differentiation IS possible between distinct genres.
One of the project's unrealized goals was to find a way to classify a song's "popularity," thus making it possible to predict how successful a new song might be. However, this would require a known standard for measuring individual song popularity, which is somewhat diluted by distinction between "song" and "record," and skewed by variables such as date of release. It would have been a fine goal, though: some sort of "musical success engine."
 This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.